A Computer’s First Step Towards Self Sufficiency
When you build a computer from scratch, you run into a serious problem. In order to program it, you have to pull the ROM out of the socket, erase it, reprogram it, and plug it back in.
Every.
Single.
Time.
Doesn’t matter if you want to change the entire ROM, one byte, or even just one bit. You’re bound to break something, with all that socket jousting.

Thankfully this ROM pin just so happens to be a dummy pin.

Erasing ROMs also wears them out. Assuming the ROM can even be erased in the first place!
The solution is to burn the ROM with just enough code that it can handle basic I/O, read data out, write data in, and make the CPU execute new code. These functions are just barely sufficient to get the system self-hosted. Collectively, we call that a ROM monitor.
Given the lack of other options (and distinct lack of other progress) on my 6502 systems, a ROM monitor is a necessary step forward for any further development. Modular Monitor is the first step towards a much more complicated text based interface, which I’m building out in stages.
ROM Monitor Basics
A ROM monitor is one of those things that can be as simple or as complicated as you want it to be. On the high end, the ROM monitor is effectively a mini OS. You can assemble or disassemble code, break into a debugger when something goes wrong, check the CPU’s internal state, and load/store files from a disk.
On the low end, a ROM monitor is a minor step up from the switch-flipping barbarism of the very first computers.
Guess which one is easier to implement.
In practice you only need six things to get a ROM monitor up and running:
- Character based input
- Character based output
- A way to put raw data into arbitrary memory locations
- A way to read out raw data from arbitrary memory locations
- A way to redirect execution to an arbitrary memory location
- Enough glue logic to strap everything together
It may be inconvenient, but you can do all your programming using this kind of ultra-minimalist monitor. A whole generation of programmers learned their craft doing the computer science equivalent of banging rocks together with this kind of ROM monitor.
Modular Monitor Overview
Software- even simple software- is very complicated. Anything you can do to keep things from spiraling out of control, you should do.
One of the most important things is to have a clear, concise idea of what you’re trying to do. This applies to every level- you should be able to do this for the entire program as a whole, each little subroutine, and even every line of assembly/machine code.
Here’s some high-level design decisions I made, and the reasons why.
Modular Design
An idea I hit upon early on was to separate separate all parts of the ROM monitor into self contained modules. Hence, Modular Monitor. Do it correctly, and you can slot new functions in with minimal effort. Old modules can be rewritten so long as they take the same inputs and produce the same outputs.
In order to make this idea work, you have to stick to some rules. Pass parameters in designated locations, don’t just reach into another module. Don’t take on any unrelated responsibilities. Stick to the once-and-only-once principle. As always, never make anything more complicated than it has to be.
Not everything is going to be done properly in the first version of Modular Monitor. There are a few shortcuts I’m willing to take to get things working. What I am trying to do is to make sure said shortcuts can be written out later.
MM Syntax
All of Modular Monitor’s user interface is based around a serial terminal. Commands are typed in as ASCII characters with LF-only terminators. Backspace and delete are respected. All other control characters are ignored.
Only capital letters are used for commands. Whitespace is ignored. Numeric values are hexadecimal.
Example syntax of MM 1.0 commands:
R 1234 56
W 1234 A5 5A AA 55
X ABCDThis is a very, very simple syntax. It has to be, because assembly programming is hard. Never make anything more complicated than it needs to be!
Using one letter means only 26 commands are possible; though I find it difficult to come up with more than a handful. Parsing strings is complicated, and I simply do not need that functionality right now. I’ll have to do it eventually, but not today.
ca65
Part of the reason I’m doing this project is because I need to get experience working with ca65. Modular Monitor happens to be a good, relatively low stakes way to do just that. ca65 has a few unusual features that have significant impact on how things get programmed.
Calling convention is based closely on cc65’s internal convention. High byte in X, low byte in A. Several dedicated zero page locations are set aside for temporary parameter storage. Hopefully this will allow interoperability with cc65 later on.
ca65 outputs special relocatable assembly. Unlike most assemblers, you don’t say things like ORG $1000. Instead you say .CODE, then tell the ld65 linker that .CODE starts at $1000. You can change the location of .CODE without changing your assembly files. Once you get the hang of it, it makes things much easier.
ca65 has a lot of tools that make assembly programming more tolerable. Among them is the concept of a “local” label. If you’ve never programmed assembly before, you won’t appreciate how useful this is. With a single ‘@’ you suddenly don’t have to come up with a thousand different variations of “LOOP” labels.
MM Software Modules
In order to get the basics bootstrapped, eight distinct modules must be implemented.
- MAIN
- RECEIVE
- SEND
- READ
- WRITE
- EXEC
- BINTOHEX
- HEXTOBIN
These map directly to the six responsibilities I mentioned before. BINTOHEX and HEXTOBIN are not explicitly part of those six, but they are required to make Modular Monitor work.
MAIN
MAIN is the primary logic behind the user interface. It handles the task of figuring out which module to run. After that, it’s up to the called module to do what it does.
Up front a handful of initialization stuff runs. An introduction string is printed to the terminal to show we’re ready. NEW_LIN and INT_Y are initialized to zero. Then go into a busy-wait loop.
.CODE
INIT:
LDA #<INTRO
STA PTR1
LDA #>INTRO
STA PTR1+1
JSR SENDSTR
STZ NEW_LIN
STZ INT_Y
CLI ;Interrupts ON
MAIN:
STZ NEW_LIN
STZ INT_Y
LDA #$3E ;Print '>' just to show we're up and running
STA SER_DAT
LDA #$7F
STA SER_FLAG ;Serial interrupts ON
@WAIT:
LDA NEW_LIN ;Wait on semaphore
BEQ @WAIT Leaving the loop means we’ve got a new line ready. At this point, we take the first character off the input buffer. This is compared to a list of known commands. On a hit, go to the associated module. Otherwise print the invalid command error message.
;Dispatch via linear search. Inefficient, but it does the job (for now)
LDA CBUFF
CMP #'R'
BNE @WR
JMP READ
BRA MAIN
@WR:
CMP #'W'
BNE @EX
JMP WRITE
BRA MAIN
@EX:
CMP #'X'
BNE @ER
JMP EXEC
BRA MAIN
@ER:
LDA #<NOCOM
STA PTR1
LDA #>NOCOM
STA PTR1+1
JSR SENDSTR
BRA MAIN ;Return to main loopMy dispatch routine is quite scruffy. There are cleverer ways to do it- using the letter as an index into a jump table, for example- but a linear search is more flexible.
Modules are direct threaded using JMP instructions. This allows a few minor optimizations. You can’t do a relative or indirect jump to subroutines on the 6502 anyways. Not without some serious work.
RECEIVE
RECEIVE is a more or less identical copy of the routine I used to figure out my RAM decoding was busted. It’s a, uh, story unto itself. I know it works, I simply had to tweak a few things here and there. Mostly labels. Also getting it into ca65 syntax.
;========== Receive interrupt ==========
RECEIVE:
PHA
PHY
LDY INT_Y ;Load interrupt Y
RLOOP: ;Read all available chars from serial port
BIT SER_FLAG ;Get flags, bit 6 is data available signal
BVS REXIT ;V set means no new data
LDA SER_DAT
STA SER_DAT ;Echo char
CMP #LF
BEQ CHR_LF
CMP #BS
BEQ CHR_BS
CMP #33 ;Non whitespace chars are >32
BCS CHR_PRINT
BRA RLOOP
CHR_BS: ;Backspace: move back one space. Simple as that
CPY #$00 ;When Y = 0 nothing more can be backspaced
BEQ RLOOP
DEY
LDA #' '
STA SER_DAT ;Overwrite output with blank space
LDA #BS
STA SER_DAT ;Ensure the cursor remains over the removed char
BRA RLOOP
CHR_LF: ;Line feed: clear Y, set NEW_LIN
LDA #00
STA CBUFF, Y ;Convert LF to NULL
LDA #$FF
STA NEW_LIN
LDY #$00
BRA REXIT
CHR_PRINT: ;Printing chars go in the buffer
STA CBUFF, Y
INY
BRA RLOOP
REXIT: ;Exit from int
STY INT_Y ;Store interrupt Y
PLY
PLA
RTIAs before, RECEIVE uses an interrupt to grab incoming characters off the serial port. Control characters are filtered out. Important control characters are interpreted directly.
Backspace now “properly” clears the output. This is done by writing a space character over the removed character. It’s purely a visual feature.
Linefeeds are silently converted to NULL. This isn’t strictly necessary, but strings are NULL terminated- for now at least.
Spaces are silently stripped from the input stream. Whitespace is ignored, so the space isn’t considered a printing character.
Many of these tweaks were done to simplify Modular Monitor. They might have to be rolled back later. We’ll see.
SENDSTR
SENDSTR is also based on previous work. Unlike RECEIVE it had to be completely remodeled.
Now SENDSTR takes a pointer via the zero page. That allows it to send any string regardless of where it’s located. As before, the string’s end is signaled by a NULL character.
;========== Send routine ==========
SENDSTR: ;NULL terminated string, pointer passed in PTR1
LDY #00
@LOOP:
LDA (PTR1), Y ;Index via PTR1
CMP #NULL
BEQ EXITS
STA SER_DAT
INY
BEQ EXITS ;Guard against infinite loop
BRA @LOOP
EXITS:
RTSThe main modifications were changing to a subroutine structure and using indirect indexed addressing. Both make SENDSTR into a generic helper routine that can be called in any context.
BINTOHEX
BINTOHEX converts one binary byte into two ASCII-hexadeicmal characters. There are a few ways to do this, but I settled on a simple addition technique. This only works for ASCII; a similar algorithm should work for other character sets.
BIN2HEX: ;Parameters are passed w/ high byte in X, low byte in A
PHA ;Backup A
AND #$F0 ;Strip off high nibble
LSR
LSR
LSR
LSR
JSR NIBTOHEX
TAX
PLA
AND #$0F
NIBTOHEX:
CMP #$0A ;Greater than 10?
BCS @HEX ;Branch greater or equal
ADC #'0'
RTS
@HEX:
ADC #'A'-11 ;11, because the carry is already set!
RTSNote the trick of jumping forwards to eliminate common code. Assembly language programming makes heavy use of tricks like this. I dislike them since they make reading/maintaining code very difficult. This one is reasonably straightforward, so I’m keeping it in.
A side effect of this trick is that NIBTOHEX is a self-contained routine that can be called independently of BINTOHEX. There may be a few ways to exploit that.
While I did come up with my own original algorithm, this snippet is actually a direct copy of the one published in Programming the 65816 (see page 322). No sense in inventing your own buggy solution when someone else has a much better one lying around. Minor adjustments were made to get 65816 code working on the 6502, but that hardly counts as “original work”.
HEXTOBIN
HEXTOBIN converts two ASCII-hexadecimal characters into one binary byte. Much like BINTOHEX, it uses a simple bitwise algorithm. Again this only works with ASCII, but the underlying principle should work with most character sets.
HEX2BIN: ;Low byte in A, high byte in X
PHA ;Backup A
TXA
CMP #'A'
BCC @NUM1 ;Less than 'A'?
SBC #7 ;Diff between 'A' and ':'
@NUM1:
AND #$0F
ASL ;ASL shifts left, pads with zeroes
ASL
ASL
ASL
STA TMP1 ;Store partial conversion
PLA
CMP #'A'
BCC @NUM2 ;Less than 'A'?
SBC #7 ;Diff between 'A' and ':'
@NUM2:
AND #$0F
ORA TMP1 ;Merge partial results
RTSMay I state clearly, that I am really upset that the 6502 can’t do any real register-register operations? If I could use X instead of TMP1, things would be faster and I’d save a byte of memory.
Unsurprisingly, HEXTOBIN is the algorithmic reverse of BINTOHEX. The main difference is I’m using an AND instruction to strip off the upper bits. This should also make uppcase/lowercase irrelevant.
Unlike HEXTOBIN, this is entirely my own programming. There’s probably a clever way to factor out the common code, but at this point I’m just trying to get things working.
READ
Finally, after four helper modules, can we start discussing the first functional module. READ takes a four digit hexadecimal address, and an optional count. For each count it fetches a byte from (PTR2), converts it to hexadecimal, prints said value, and increments PTR2.
;========== READ routine ==========
;Takes a 4 digit hex address, a 2 digit hex count, and prints the results
READ:
;Begin by interpreting the address
LDY #01 ;Start at 1 char beyond start
STZ TMP2
LDX CBUFF, Y ;Strings are big-endian
INY
LDA CBUFF, Y
INY
JSR HEX2BIN
STA PTR2+1
LDX CBUFF, Y ;Strings are big-endian
INY
LDA CBUFF, Y
INY
JSR HEX2BIN
STA PTR2
;Check if next char is NULL, which is end of string
LDX CBUFF, Y
BEQ @NOCOUNT
INY
LDA CBUFF, Y
BEQ @NOCOUNT
JSR HEX2BIN
INC A
TAY
BRA RDLOOP
@NOCOUNT:
LDY #01
RDLOOP:
;Fetch data using PTR2
LDA (PTR2)
JSR BIN2HEX
STX SER_DAT
STA SER_DAT
LDA #' '
STA SER_DAT
INC PTR2
BCC @NOINC
INC PTR2+1
@NOINC:
;TMP2 breaks the output into 16 byte lines for readability
INC TMP2
LDA #16
CMP TMP2
BNE @SKIP
LDA #LF
STA SER_DAT
STZ TMP2
@SKIP:
DEY
BNE RDLOOP
LDA #LF
STA SER_DAT
JMP MAINPretty simple, when you get right down to it.
There’s a lot of repeated code that might be factored out later on. Converting a 4 digit hexadecimal number is common enough it might do better as it’s own routine.
I chose not to use SENDSTR for output in the interest of speeding up development. A much better solution would be to assemble each line in RAM. then output using SENDSTR. You can do some fun things with that.
WRITE
WRITE is almost identical to READ. Indeed, the first half is completely identical. After sorting out the address, we take characters off the input buffer. Pairs of characters are converted to binary, then stored at the location in (PTR2). Continue the process until we get a NULL.
;========== WRITE routine ==========
;Takes a 4 digit hex address, and any number of 2 digit hex data
WRITE:
;Begin by interpreting the address
LDY #01 ;Start at 1 char beyond start
LDX CBUFF, Y
INY
LDA CBUFF, Y
INY
JSR HEX2BIN
STA PTR2+1
LDX CBUFF, Y
INY
LDA CBUFF, Y
JSR HEX2BIN
STA PTR2
;Interpret character pairs as hexadecimal, write to (PTR2)
WRLOOP:
INY
LDX CBUFF, Y
BEQ @EXIT ;Stop if NULL
INY
LDA CBUFF, Y
BEQ @EXIT ;Stop if NULL
JSR HEX2BIN
STA (PTR2)
INC PTR2
BCC @NOINC
INC PTR2+1
@NOINC:
BRA WRLOOP
@EXIT:
JMP MAINThere are some obvious problems here. Strings longer than 256 bytes will simply break the algorithm. A standard terminal line is at most 82 characters, so I’m not going to worry about it.
EXEC
Outside of stack manipulation, there is no way to redirect the 6502 only using read or write commands. If the code was in RAM we could insert a JMP or BRx instruction. MM is run out of ROM though, so that isn’t possible.
Instead we translate a hexadecimal address, then use JMP indirect to… jump to the new thread of execution.
;========== EXEC routine ==========
;Takes a 4 digit hex address, jumps directly to it
EXEC:
;Begin by interpreting the address
LDY #01 ;Start at 1 char beyond start
LDX CBUFF, Y
INY
LDA CBUFF, Y
INY
JSR HEX2BIN
STA PTR2+1
LDX CBUFF, Y
INY
LDA CBUFF, Y
JSR HEX2BIN
STA PTR2
JMP (PTR2)EXEC is by far the simplest module. It takes no parameters, so as soon as we have the address it can proceed.
Testing Modular Monitor
ROM monitors are often used to test and debug code. That’s kind of why they exist to begin with. But, how do you debug the debugger? Hmm…
With a little care, it’s possible to make MM- or any monitor- do most of it’s own testing!
Testing READ
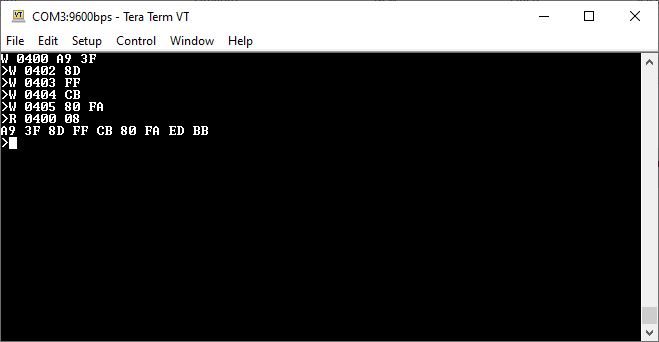
READ is by far the easiest function to test. It’s also the only way to check if any part of MM is actually working. READ is tested by reading out MM’s own source code. Here’s a comparison of the associated READ statement and the MM ROM image:


As you can see, the live output matches the ROM image.
READ is easy to test. It’s not really possible to break anything, and as long as we know what the output should be, we can simply look at the result. If it looks good, it is good.
Most of the debugging effort was actually debugging HEXTOBIN. My original solution didn’t really work, but switching from SBC to AND fixed everything.
The other big issue was loading the partial address bytes the right way around. 6502s are strictly little-endian, but strings are big-endian! Sort of! It gets complicated.
After that it worked perfectly.
Testing WRITE
WRITE is relatively easy to test, but it’s much easier to test when READ is working. The obvious test is to simply write some known values to a random spot in RAM, then read them back. Let’s do exactly that:

Works fine. But a more interesting test is to write to the serial port directly:

WRITE‘s big bug was using (PTR2), Y instead of just (PTR2). Dunno why I though Y ought to be there (maybe copy/paste syndrome?), but the consistent off-by-two error was enough to tip me off.
There appears to be a different persistent bug in WRITE where if the second digit in a pair is a letter, the routine prematurely exits. This only seems to occur when WRITE is writing; addresses with trailing hex digits work perfectly.
I’m not entirely sure why this happens. My guess is that HEXTOBIN is tripping some flag that WRITE picks up. How or why this happens is unknown; LDA should clear the relevant flags automatically.
Testing EXEC
EXEC is only really useful when there’s new code to execute. Typing in a short test program using WRITE is an option- but there’s an easier way. Just jump back to the start of the monitor!

At this point my code was working the first time. EXEC required no special debugging.
Putting it All Together
I said that these three functions are sufficient to program. Let’s prove that using an example.
First, come up with a very basic program that won’t be hard to debug. My program is a short loop that prints a single character to the serial port forever.

This is the simplest possible program that still produces terminal output.
Notice this is all written on paper. You don’t need fancy-ass programming software. All you really need is pencil, paper, the CPU datasheet, and some idea of the target system’s internals.
I chose a starting address of $0400 because it’s easy to remember, is definitely in the RAM, and won’t collide with Modular Monitor. The serial port is at a fixed address of $CBFF. That’s all the machine specific stuff we need to know.
Translate assembly to machine code using the opcode table. Keep in mind the various addressing modes. Also remember the 6502 is little endian, so the lower byte of an address comes first.
This process is, somewhat euphemistically, known as “hand assembly”.
When I was taking computer architecture, we were asked to assemble four lines of MIPS code on an exam.
I don’t remember getting any of them right.

Every 6502 datasheet has something like this table. You simply find the instruction+addressing mode in the table, and look up the associated hexadecimal digits.
Taken directly out of the W65C02 datasheet.

Once you have the desired program written out, translate each line using the opcode table. Fill in constants as needed.
Notice the MM statements don’t work around the trailing hex bug- I had to refactor that manually.
From there it’s simply a matter of typing in the assembled code, verifying it, and executing it. This is the tricky bit. A single typo spoils the whole lot.


There. Now you can call yourself a Real Programmer.
Finishing Up
I’ve been putting off writing a monitor for my 6502 development board for… a year? From the records I’ve got, I finished the development board article exactly one year ago. Of course that included the very first 6502 program I ever wrote, the debugging of said program, and some serious hardware fixes not detailed in that article. Let’s call it a year in the making.
After a year of tepid progress, I set aside a snowy weekend to finally try writing Modular Monitor. The features shown here were working in maybe six hours. Six hours, after a year of blech effort. I guess 2023 is the Year of Getting Stuff Done.
Part of the reason things took so long is I’m really not happy with my minimal development board. It’s underpowered, inflexible (software), too flexible (physical), and just can’t do the things I want it to. The UM245R has proven to be particularly problematic. I have a much better design that should be ready to go relatively soon.
While I still have the minimal development board, I’m going to try my hand at much larger, more complex programs. I’m distinctly limited (e.g. the board has no interrupt timer), but there’s things I can do inside those limits. 6502 programming is very difficult. Any chance to learn how to use it better can’t just be passed up.
Modular Monitor is only in it’s most basic form. I have many, many, ideas for how to improve it. Error handling is probably the highest priority. Cleaning up the MM source code is another big one. Programming the ROM in-circuit is probably the most desirable; unsocketing the ROM has a nonzero chance of breaking something.
The 6502 minimal development board is one of my most popular articles. I feel just a touch embarrassed by that- it’s terrible. But, it’s still a functional 6502 computer. For that, at least, I can be a little proud.
I don’t know what the next 6502 project is going to be. Right now I’m going to focus on improving Modular Monitor- there’s a lot of interesting stuff to cover there. At some point I’m going to have to switch to my new development board.
I suppose we’ll all just have to wait for it to happen. No sense going faster than I can keep pace with.
Have a question? Comment? Insight? Post below!